Optimize Pagination Speed with Asynchronous Queries in Ruby on Rails
In any Rails application that deals with large amounts of records, you will most certainly reach for pagination to "window" your data instead of rendering it in one long list.

To contextualize the following deliberations, we are going to assume that we are dealing a real world, complex use case that requires:
- the actual grouping of records,
- the ability to jump forward and backward between pages, or to a particular one,
- and an overview of the pagination metadata, including the count of records and pages.
The last requirement in particular rules out simpler, more efficient pagination techniques such as:
- Countless pagination, where calculating a total count is left out completely in favor of discovering new pages on the fly by requesting one additional record exceeding the current window (like with infinite scrolling). Thus each page only knows whether it has a “next” and “previous” neighbor, or
- Keyset pagination, which uses an optimized “SQL Seek” technique and is primarily applicable to APIs, but of limited use for UIs because it only provides access to the “first” and “next” pages (not the “last” or “previous” ones).
Thus, the code performing the pagination will have two responsibilities:
- retrieving the actual windowed results using a potentially complex SQL query that can become quite slow (something like
SELECT ... LIMIT ... OFFSET), plus - calculating the total amount of records from which to draw the paginated ones, triggering a second query (
SELECT COUNT ...).
In this blog post, we will look at ways to speed up page rendering by issuing these two queries concurrently instead of consecutively.
To demonstrate this we best start from a real world, sufficiently complex use case. Why “sufficiently complex”? Because the profits of Rails’ asynchronous database capabilities are best shown and felt when the underlying query takes a substantial amount of time.
Hence, as an example application, let’s build a directory to list interesting souvenirs from around the world. This will lead to a faceted search interface using tags and geolocation which should help us illustrate the benefits of the proposed optimization.
Preparations
Places
First of all, we need a list of places. I’ve sourced them from the countries and cities gems, but the process in detail isn’t relevant to this post.
Let’s assume that a (very) broken down schema of the Place model might look like this:
$ bin/rails g model Place name:string geo:json
$ bin/rails db:migrate
The imported list from the sources mentioned above contains 17,060 places, including countries, cities, regions, provinces etc.
Souvenirs
Next, we are going to add the Souvenir model. It will contain a title and description attribute, as well as a reference to a place.
$ bin/rails g scaffold Souvenir title:string place:references description:text
We’d also like to add tags to our souvenirs. The acts-as-taggable-on gem is the one stop solution to do that, so we are going to install it:
$ bundle add acts-as-taggable-on
It uses a polymorphic many-to-many association to our Souvenir model under the hood, so we have to install the respective database migrations and execute them:
$ bin/rails acts_as_taggable_on_engine:install:migrations
$ bin/rails db:migrate
Finally, this is what our Souvenir model looks like: a belongs_to association to a place, and tags set up by the acts_as_taggable_on class method:
# app/models/souvenir.rb
class Souvenir < ApplicationRecord
belongs_to :place
acts_as_taggable_on :tags
end
Now, let’s use Faker to add some seed data:
Place.all.find_each do |place|
rand(4).round.times do
place.souvenirs << Souvenir.new(
title: Faker::Lorem.word.capitalize,
description: Faker::Lorem.sentence,
tag_list: Faker::Lorem.words(number: rand(3).round + 1).join(", ")
)
end
end
After executing that, our database contains 25,687 souvenirs and 182 tags.
Souvenirs Controller
Now it’s time to display these souvenirs in a list. For this, we’ll create a standard Rails controller containing an index route:
# app/controllers/souvenirs_controller.rb
class SouvenirsController < ApplicationController
# GET /souvenirs
def index
Souvenir.all.includes(:place, taggings: :tag)
end
# etc...
end
Quite obviously, it’s not feasible to display over 25,000 records on a single page, so we need pagination. The Pagy gem is our library of choice here, for reasons of simplicity and speed. Let’s add its Backend module to the controller first. This allows us to use the pagy factory helper to create a windowed collection of records:
# app/controllers/souvenirs_controller.rb
class SouvenirsController < ApplicationController
+ include Pagy::Backend
# GET /souvenirs
def index
- Souvenir.all.includes(:place, taggings: :tag)
+ @pagy, @souvenirs = pagy(Souvenir.all.includes(:place, taggings: :tag))
end
# etc...
end
Next, by including Pagy::Frontend in your view helpers (e.g. ApplicationHelper), its output methods pagy_nav and pagy_info are at your disposal. We can now use them to display information about the pagination window and a navigation bar:
<div id="souvenirs">
<%= pagy_info(@pagy, item_name: "souvenirs") %>
<% @souvenirs.each do |souvenir| %>
<%= render souvenir %>
<% end %>
<%= pagy_nav(@pagy) %>
</div>
Here’s a screenshot of this view rendered out:
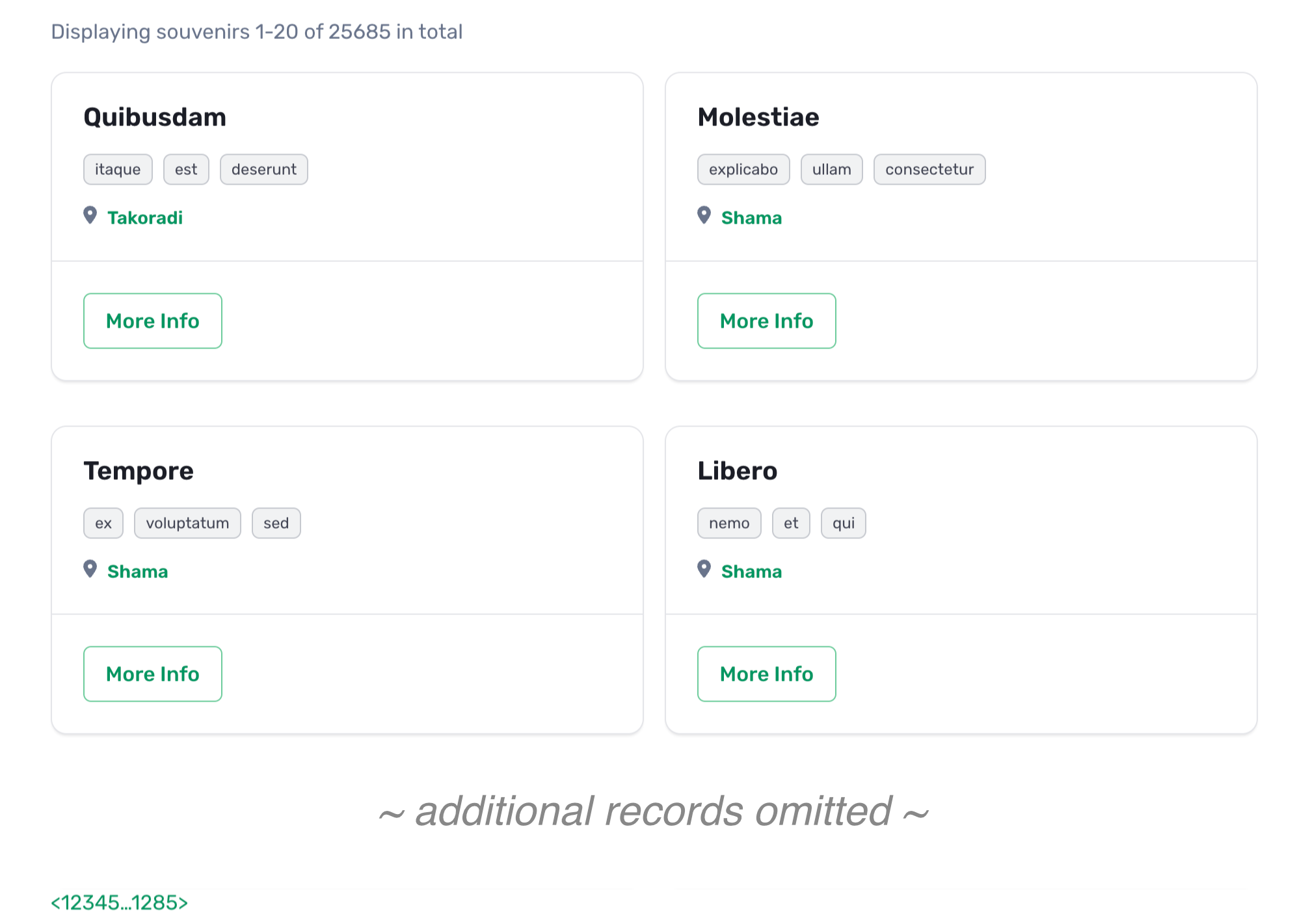
Adding Faceted Search
With all this in place, we are now ready to add faceted search to our application. Certainly it would be desirable to filter souvenirs for their tags, and sort them by distance to the user’s current location.
# app/controllers/souvenirs_controller.rb
class SouvenirsController < ApplicationController
include Pagy::Backend
# GET /souvenirs
def index
- @pagy, @souvenirs = pagy(Souvenir.all.includes(:place, taggings: :tag))
+ query = Souvenir.all.includes(:place, taggings: :tag)
+ query = query.joins(:tags).where(tags: params[:tags]).distinct if params[:tags].present?
+ @pagy, @souvenirs = pagy(query)
end
# etc...
end
Note that we have to add a JOIN to the tags table (which are actually two joins because of the has_many ... through: ... relationship), and above all a DISTINCT clause to filter out duplicates. If you’ve had your fair share of database performance headaches, you know that DISTINCT is always costly.
Next, we’ll calculate the distance to our current position (assume that it’s transmitted with the form data) and use that to sort by descending proximity. We’ll use the Harvesine formula to do this. Note that the mentioned haversine SQL function is not a native one but was added by the author.
# app/models/places
class Place < ApplicationRecord
# ...
+ scope :near, ->(lat, lng) { order(Arel.sql("haversine(places.geo ->> '$.latitude', ?, places.geo ->> '$.longitude', ?)", lat, lng)) }
end
# app/controllers/souvenirs_controller.rb
class SouvenirsController < ApplicationController
include Pagy::Backend
# GET /souvenirs
def index
query = Souvenir.all.includes(:place, taggings: :tag)
query = query.joins(:tags).where(tags: params[:tags]).distinct if params[:tags].present?
+ query = query.joins(:place).merge(Place.near(params[:latitude], params[:longitude]))
@pagy, @souvenirs = pagy(query)
end
# etc...
end
With this change, we’ve sufficiently approximated a real world scenario for faceted search. Indeed, the resulting SQL query is quite complex, and time consuming:
-- SQL (247.1ms)
SELECT DISTINCT "souvenirs"."id"
FROM "souvenirs"
INNER JOIN "taggings" ON "taggings"."taggable_type" = 'Souvenir' AND "taggings"."context" = 'tags' AND "taggings"."taggable_id" = "souvenirs"."id"
INNER JOIN "tags" ON "tags"."id" = "taggings"."tag_id"
INNER JOIN "places" ON "places"."id" = "souvenirs"."place_id"
LEFT OUTER JOIN "taggings" "taggings_souvenirs" ON "taggings_souvenirs"."taggable_type" = 'Souvenir' AND "taggings_souvenirs"."taggable_id" = "souvenirs"."id"
LEFT OUTER JOIN "tags" "tags_taggings" ON "tags_taggings"."id" = "taggings_souvenirs"."tag_id" WHERE "tags"."id" = '01jcx5w8fxpw5k6rmnvp5jt4d1'
ORDER BY haversine(places.geo ->> '$.latitude', 46.2048226, places.geo ->> '$.longitude', 6.1018393)
LIMIT 20 OFFSET 0
What exacerbates matters, though, is that we execute two queries in this case:
- One for actually loading the souvenirs in the pagination window (like above),
- And one to calculate the total count of records matching the search query, to be displayed in the overall info box:
-- Souvenir Count (65.6ms)
SELECT COUNT(DISTINCT "souvenirs"."id")
FROM "souvenirs"
INNER JOIN "taggings" ON "taggings"."taggable_type" = 'Souvenir' AND "taggings"."context" = 'tags' AND "taggings"."taggable_id" = "souvenirs"."id"
INNER JOIN "tags" ON "tags"."id" = "taggings"."tag_id"
INNER JOIN "places" ON "places"."id" = "souvenirs"."place_id"
LEFT OUTER JOIN "taggings" "taggings_souvenirs" ON "taggings_souvenirs"."taggable_type" = 'Souvenir' AND "taggings_souvenirs"."taggable_id" = "souvenirs"."id"
LEFT OUTER JOIN "tags" "tags_taggings" ON "tags_taggings"."id" = "taggings_souvenirs"."tag_id"
WHERE "tags"."id" = '01jcx5w8fxpw5k6rmnvp5jt4d1'
In total, this amounts to 313ms spent querying the database in this simple case. It is here that we can begin to start thinking about optimizing, because these queries are executed sequentially when they could just as well be run in parallel.
Here’s a look on the updated user interface:
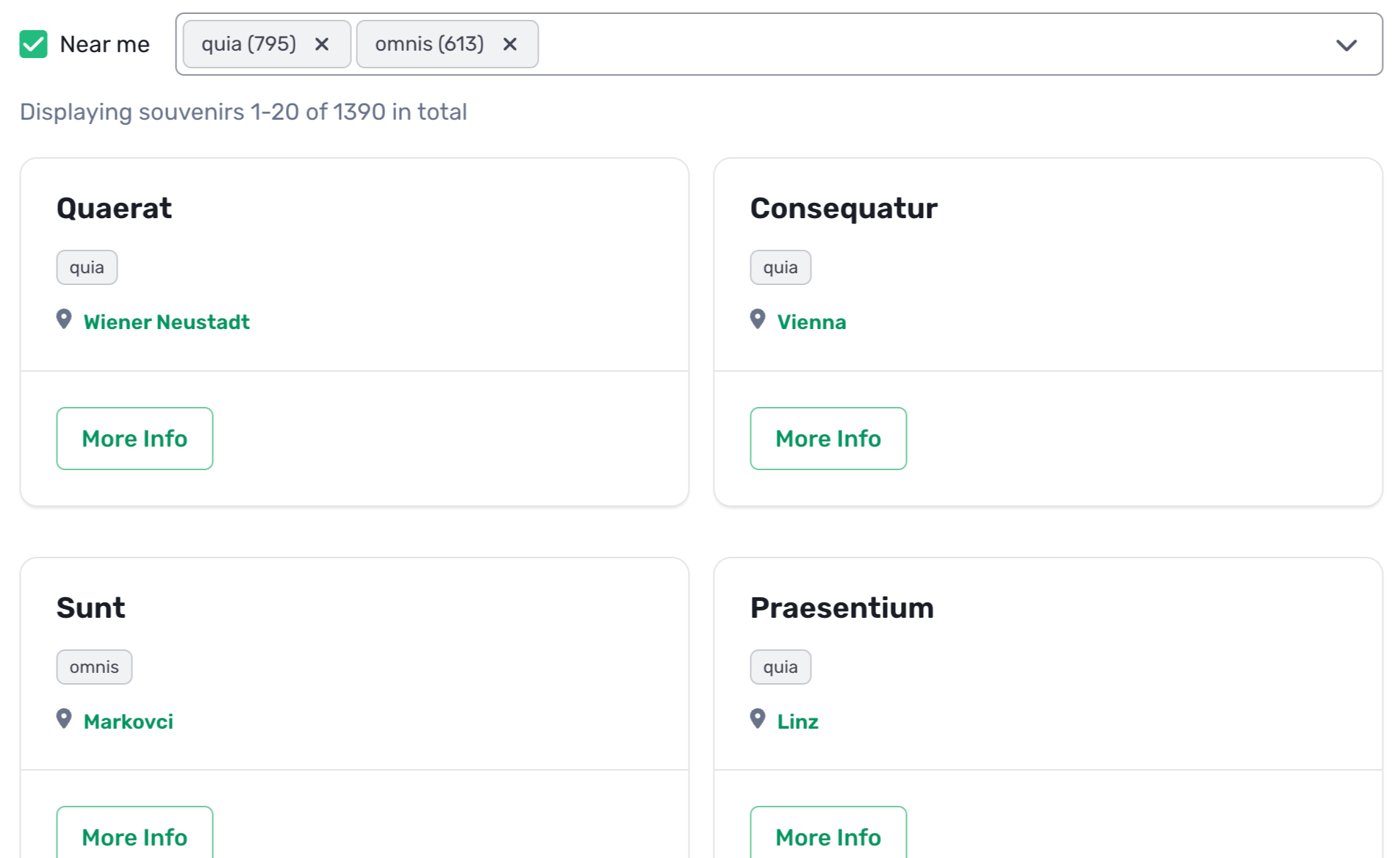
Executing Database Queries Concurrently
Rails 7.0.1 introduced a way to execute SELECT statements from a background thread pool using the ActiveRecord::Relation#load_async method. In Rails 7.1, this has been expanded to a general ActiveRecord API for asynchronous queries.
The gist is that you can prepend async_ to methods like count, maximum, pluck, pick etc. and the return value changes to an ActiveRecord::Promise. This will only be resolved once you call the value method on it, returning the query result.
In our case, we will implement asynchronous calculating the total record count. Fortunately, the Pagy Backend API allows easy local overriding of getter methods like pagy_get_count, which is even encouraged in the official docs.
So without further ado, let’s give this a try in our SouvenirsController:
class SouvenirsController < ApplicationController
# ...
private
+ def pagy_get_count(collection, _vars)
+ collection.async_count(:all).value
+ end
# ...
end
This implementation discards the precautions that the original Pagy method sports for cases that are dealing with non-ActiveRecord collections. Instead we perform an async_count query and resolve it by calling value.
Using this approach will still not result in the query being executed from the background thread pool though, because you have to configure the async query executor, e.g. in your config/application.rb:
# config/application.rb
class Application < Rails::Application
# ...
+ config.active_record.async_query_executor = :global_thread_pool
end
Equipped with this setup, let’s issue the same query as before and watch the logs:
-- SQL (76.5ms)
SELECT DISTINCT "souvenirs"."id"
FROM "souvenirs"
INNER JOIN "taggings" ON "taggings"."taggable_type" = 'Souvenir' AND "taggings"."context" = 'tags' AND "taggings"."taggable_id" = "souvenirs"."id"
INNER JOIN "tags" ON "tags"."id" = "taggings"."tag_id" INNER JOIN "places" ON "places"."id" = "souvenirs"."place_id"
LEFT OUTER JOIN "taggings" "taggings_souvenirs" ON "taggings_souvenirs"."taggable_type" = 'Souvenir' AND "taggings_souvenirs"."taggable_id" = "souvenirs"."id"
LEFT OUTER JOIN "tags" "tags_taggings" ON "tags_taggings"."id" = "taggings_souvenirs"."tag_id"
WHERE "tags"."id" = '01jcx5w8fxpw5k6rmnvp5jt4d1'
ORDER BY haversine(places.geo ->> '$.latitude', 46.2048226, places.geo ->> '$.longitude', 6.1018393)
LIMIT 20 OFFSET 0
-- ASYNC Souvenir Count (0.0ms) (db time 23.3ms)
SELECT COUNT(DISTINCT "souvenirs"."id")
FROM "souvenirs"
INNER JOIN "taggings" ON "taggings"."taggable_type" = 'Souvenir' AND "taggings"."context" = 'tags' AND "taggings"."taggable_id" = "souvenirs"."id"
INNER JOIN "tags" ON "tags"."id" = "taggings"."tag_id" INNER JOIN "places" ON "places"."id" = "souvenirs"."place_id"
LEFT OUTER JOIN "taggings" "taggings_souvenirs" ON "taggings_souvenirs"."taggable_type" = 'Souvenir' AND "taggings_souvenirs"."taggable_id" = "souvenirs"."id"
LEFT OUTER JOIN "tags" "tags_taggings" ON "tags_taggings"."id" = "taggings_souvenirs"."tag_id"
WHERE "tags"."id" = '01jcx5w8fxpw5k6rmnvp5jt4d1'
The windowed query coincidentally ran faster than before. More importantly, note the ASYNC Souvenir Count entry in the logs which reports an execution time of (0.0ms) (db time 23.3ms). This denotes the time the main thread was blocked (0ms) vs the time actually spent querying the database (23.3ms). The conclusion, thus, is that we saved about 23ms of total request time. Not bad!
An Important Caveat
This sounds like a silver bullet (async all the things!), but of course there’s one important catch. Does the dreaded ActiveRecord::ConnectionTimeoutError ring a bell? If you’re not careful, using asynchronous queries you will inadvertently run into this error.
Why is that?
The reason is that background database threads aren’t created from a magical cornucopia, but need to be drawn from the database pool. By default, Rails adds 4 background threads for each puma worker (though this setting can be customized).
Let’s do the napkin math: If we run our worker with 3 threads each (the current default) and add 4 threads, each worker consumes 7 database connections.
Say we run 3 workers, then this already sums up to 21 concurrent threads querying the database. Add Sidekiq to the setup, and this calculation needs to be adapted to include Sidekiq concurrency. For example, a Sidekiq worker with 5 threads needs an additional 4. In total, we’re at 30 connections now. The critical point is to balance this against your database’s connection limit. Leave ample overhead to never run out of connections, else you’ll run into the aforementioned error and your app will freeze.
Moreover, you should keep in mind that inevitably opening more connections will also consume more resources (CPU, memory, swap space) in your database server. Hence you should only enable this when you have good monitoring in place to observe your database’s load.
For a deep dive into the mechanics of async loading, take a look at Pawel Urbanek’s exhaustive article.
Round Up
In this article, we explored optimizing pagination speed in Ruby on Rails applications by utilizing asynchronous database queries. Offset pagination with full UI and info relies on two queries that are executed sequentially by default: one to count the total records and another to fetch paginated results. This can lead to significant latency, especially with complex queries.
By implementing Rails’ asynchronous query capabilities introduced in version 7.0.1 and expanded in 7.1, developers can run these queries concurrently. We used a practical example of a souvenir directory application to illustrate this, showcasing how to enhance a faceted search use case using the Pagy gem for efficient pagination.
We demonstrated how to override the pagy_get_count method to employ asynchronous counting, allowing the application to handle multiple database connections without blocking the main thread.
However, developers must carefully manage database connection limits to prevent ActiveRecord::ConnectionTimeoutError, especially in multi-threaded environments and with background job processors like Sidekiq.
In conclusion, embracing asynchronous queries can significantly reduce response times in Rails applications, resulting in a smoother user experience when handling large datasets.

